

こんにちは、こっしーです。
前回の記事では、開発環境の準備と Flet の基本についてご紹介しました。
今回はいよいよ「データ分析アプリ」らしく、CSV ファイルの読み込み機能を実装していきます!
「データ分析」と聞くと、難しそうなイメージがあるかもしれませんが、今回は”誰でもすぐに試せる”ように、サンプルデータを自動生成するコードも用意しました。
「まずは動くものを触ってみたい!」
「CSV ファイルの扱い方を基礎から学びたい!」
そんな方にもピッタリな内容になっています。
- Pandas を使った CSV ファイルの読み込み方法
- サンプルデータの自動生成
- データフレームの基本操作
- Flet でデータを表示する方法
- 初心者がつまずきやすいポイントとエラー対策
- Python や Flet でデータ分析アプリを作ってみたい方
- CSV ファイルの扱い方を基礎から学びたい方
- すぐに動くサンプルで手を動かしながら学びたい方
すぐに試せるサンプルデータも用意!
「自分で CSV ファイルを用意するのはちょっと面倒…」
「まずは動くサンプルで試してみたい!」
そんな方のために、サンプルデータを自動生成するコードを用意しました。
記事内のサンプルコードをそのままコピペすれば、
誰でもすぐにデータ読み込み機能を体験できるようになっています。
サンプルデータ自動生成スクリプト
import pandas as pd
import numpy as np
import os
# データ保存用ディレクトリ
os.makedirs("data", exist_ok=True)
# 説明変数データのサンプル
df_explanatory = pd.DataFrame({
"時点": [f"2023年{m}月" for m in range(1, 13)],
"売上高": np.random.randint(1000, 2000, 12),
"従業員数": np.random.randint(50, 150, 12),
"広告費": np.random.randint(100, 300, 12),
"研究開発費": np.random.randint(200, 500, 12),
})
df_explanatory.to_csv("data/explanatory_variables.csv", index=False, encoding="utf-8-sig")
# 目的変数データのサンプル
df_target = pd.DataFrame({
"date": [f"2023{str(m).zfill(2)}" for m in range(1, 13)],
"利益率": np.random.uniform(0.05, 0.15, 12).round(3),
})
df_target.to_csv("data/target_variable.csv", index=False, encoding="utf-8-sig")
print("サンプルデータを data フォルダに出力しました。")使い方
- 上記のコードを
generate_sample_data.pyなどのファイル名で保存 - ターミナルで
python generate_sample_data.pyを実行 dataフォルダに「explanatory_variables.csv」と「target_variable.csv」が生成されます
CSV ファイルの読み込み機能を実装しよう!
サンプルデータが準備できたら、いよいよ CSV ファイルの読み込み機能を実装していきます。
ファイル構成
以下のファイル構成で実装していきます:
Craft_RegressionAnalysis/
├── data/
│ └── explanatory_variables.csv # 説明変数用のCSVファイル(generate_sample_data.pyで生成)
│ └── target_variable.csv # 目的変数用のCSVファイル(generate_sample_data.pyで生成)
├── pages/
│ └── page_data_load.py # データ読み込みページ
└── main.py # メインアプリケーション0. メインアプリケーションの設定
第 1 回の記事ではシンプルなメインページでしたが、第 2 回ではデータ読み込み機能を追加するため、main.pyを以下のように修正します。
ファイル: main.py
import flet as ft
import pandas as pd
# データ読み込みページを表示
from pages.page_data_load import data_load_page
# アプリケーションデータを保持するクラス
class AppData:
def __init__(self):
self.current_page = "data_load" # 現在のページ
self.data_loaded = False # データ読み込み状態
self.merged_df: pd.DataFrame | None = None # 結合されたデータ
self.saved_df: pd.DataFrame | None = None # 保存されたデータ
self.original_df: pd.DataFrame | None = None # オリジナルデータ
self.standardized_df: pd.DataFrame | None = None # 標準化データ
def main(page: ft.Page):
"""
Fletアプリを初期化し、データ読み込みページを表示する
"""
page.title = "データ分析アプリ"
page.theme_mode = ft.ThemeMode.LIGHT
# pageにAppDataインスタンスをアタッチ
page.app_data = AppData() # type: ignore
page.add(data_load_page(page))
page.update()
if __name__ == "__main__":
ft.app(target=main)主な変更点:
AppDataクラスにデータ管理用の属性を追加current_pageを"data_load"に変更- データフレーム用の属性(
merged_df,saved_df,original_df,standardized_df)を追加
第 1 回との比較:
# 第1回のAppDataクラス(シンプル版)
class AppData:
def __init__(self):
self.current_page = "home"
self.data_loaded = False
self.merged_df = None
self.standardized_df = None
# 第2回のAppDataクラス(機能拡張版)
class AppData:
def __init__(self):
self.current_page = "data_load"
self.data_loaded = False
self.merged_df: pd.DataFrame | None = None
self.saved_df: pd.DataFrame | None = None
self.original_df: pd.DataFrame | None = None
self.standardized_df: pd.DataFrame | None = None第 1 回では基本的な構造のみでしたが、第 2 回では実際のデータ分析に必要な属性を追加しています。
1. データ読み込み関数の作成
まず、CSV ファイルを読み込んでデータフレームに変換する関数を作成します。
ファイル: pages/page_data_load.py
import os
import flet as ft
import pandas as pd
def load_initial_csv_data(page: ft.Page):
"""CSVファイルからデータを読み込む関数"""
data_folder_path = "data"
explanatory_variables_file = "explanatory_variables.csv"
explanatory_variables_path = os.path.join(
data_folder_path, explanatory_variables_file
)
target_variable_file = "target_variable.csv"
target_variable_path = os.path.join(data_folder_path, target_variable_file)
try:
# 説明変数データの読み込み
explanatory_df = pd.read_csv(explanatory_variables_path)
print(f"説明変数データ読み込み完了。シェイプ: {explanatory_df.shape}")
# 日付カラムを統一フォーマットに変換
explanatory_df["date"] = pd.to_datetime(
explanatory_df["時点"], format="%Y年%m月"
).dt.strftime("%Y%m")
# 目的変数データの読み込み
target_df = pd.read_csv(target_variable_path, dtype={"date": str})
print(f"目的変数データ読み込み完了。シェイプ: {target_df.shape}")
# 両方のデータフレームを結合
merged_df = pd.merge(explanatory_df, target_df, on="date", how="inner")
# アプリケーションデータに保存
page.app_data.merged_df = merged_df # type: ignore
print(f"データ結合完了。シェイプ: {merged_df.shape}")
return merged_df
except Exception as e:
print(f"CSVデータのロード中にエラーが発生しました: {e}")
return None
2. データ表示用のテーブルコンポーネント
次に、読み込んだデータを美しく表示するためのテーブルコンポーネントを作成します。
ファイル: pages/page_data_load.py(続き)
def create_data_table(df: pd.DataFrame) -> ft.Container:
"""データフレームを表示用テーブルに変換する関数"""
# ヘッダー行の作成
header_row = ft.Row(
controls=[
ft.Container(
content=ft.Text(col, weight=ft.FontWeight.BOLD, size=14),
width=200,
padding=ft.padding.only(left=15, right=15, top=8, bottom=8),
border=ft.border.only(
right=ft.border.BorderSide(1, ft.Colors.GREY_300)
),
)
for col in df.columns
],
alignment=ft.MainAxisAlignment.START,
)
# データ行の作成
data_listview = ft.ListView(expand=True, spacing=0, padding=0)
for row in df.itertuples(index=False):
data_row = ft.Row(
controls=[
ft.Container(
content=ft.Text(str(value), size=14),
width=200,
padding=ft.padding.only(left=15, right=15, top=8, bottom=8),
border=ft.border.only(
right=ft.border.BorderSide(1, ft.Colors.GREY_300)
),
)
for value in row
],
alignment=ft.MainAxisAlignment.START,
)
# 交互の行の背景色を設定(Containerでラップ)
if len(data_listview.controls) % 2 == 1:
data_row = ft.Container(
content=data_row,
bgcolor=ft.Colors.GREY_50,
)
data_listview.controls.append(data_row)
# テーブル全体を包むスクロール可能なコンテナ
table_container = ft.Container(
content=ft.Column(
[
# ヘッダー行(固定)
ft.Container(
content=header_row,
border=ft.border.only(
left=ft.border.BorderSide(1, ft.Colors.GREY_300),
right=ft.border.BorderSide(1, ft.Colors.GREY_300),
top=ft.border.BorderSide(1, ft.Colors.GREY_300),
),
bgcolor=ft.Colors.GREY_100,
),
# データ行(スクロール可能)
ft.Container(
content=data_listview,
border=ft.border.only(
left=ft.border.BorderSide(1, ft.Colors.GREY_300),
right=ft.border.BorderSide(1, ft.Colors.GREY_300),
bottom=ft.border.BorderSide(1, ft.Colors.GREY_300),
),
expand=True,
),
],
spacing=0,
expand=True,
),
expand=True,
)
return table_container
3. データ読み込みページの作成
最後に、これらを組み合わせてデータ読み込みページを作成します。
ファイル: pages/page_data_load.py(続き)
def data_load_page(page: ft.Page):
"""データ読み込みページ"""
page.title = "データ読み込み・参照"
# データ表示用コンテナ
content_container = ft.Container(
content=ft.Text("データを読み込んでください"),
bgcolor=ft.Colors.WHITE,
expand=True,
)
def load_data_button_click(e):
"""データ読み込みボタンのクリックイベント"""
try:
# CSVファイルからデータを読み込み
merged_df = load_initial_csv_data(page)
if merged_df is not None and not merged_df.empty:
# データテーブルを作成して表示
table_container = create_data_table(merged_df)
content_container.content = table_container
# 成功メッセージを表示
snack = ft.SnackBar(content=ft.Text("データの読み込みが完了しました!"))
page.add(snack)
snack.open = True
else:
# エラーメッセージを表示
snack = ft.SnackBar(content=ft.Text("データの読み込みに失敗しました。"))
page.add(snack)
snack.open = True
except Exception as e:
print(f"データ読み込み中にエラーが発生: {e}")
snack = ft.SnackBar(content=ft.Text(f"エラーが発生しました: {str(e)}"))
page.add(snack)
snack.open = True
page.update()
# データ読み込みボタン
load_button = ft.ElevatedButton(
"CSVファイルを読み込み",
on_click=load_data_button_click,
style=ft.ButtonStyle(
color=ft.Colors.WHITE,
bgcolor=ft.Colors.BLUE,
),
)
return ft.Container(
content=ft.Column(
[
ft.Text("データ読み込み・参照", size=20, weight=ft.FontWeight.BOLD),
ft.Divider(),
load_button,
ft.Divider(),
content_container,
],
expand=True,
),
expand=True,
)
実装のポイント
ファイル保存場所の確認
実装したコードは以下の場所に保存してください:
- メインページ:
pages/page_data_load.py - データ変換:
utils/data_transformation.py - データベース:
db/database.py - メインアプリ:
main.py
1. エラーハンドリング
try-except文を使って、ファイルが見つからない場合やデータ形式が不正な場合のエラーを適切に処理- ユーザーに分かりやすいエラーメッセージを表示
2. データの前処理
- 日付フォーマットの統一(
%Y年%m月` → `%Y%m) - データ型の指定(
dtype={"date": str}) - 欠損値の処理
3. UI/UX の工夫
- スクロール可能なテーブルで大量のデータも表示
- 交互の行の背景色で見やすさを向上
- ローディング状態や成功/エラーメッセージの表示
動作確認
ファイル構成の確認
まず、以下のファイル構成になっていることを確認してください:
Craft_RegressionAnalysis/
├── data/
│ └── explanatory_variables.csv # 説明変数用のCSVファイル(generate_sample_data.pyで生成)
│ └── target_variable.csv # 目的変数用のCSVファイル(generate_sample_data.pyで生成)
├── pages/
│ └── page_data_load.py # データ読み込みページ
└── main.py # メインアプリケーション実行手順
- サンプルデータを生成
- アプリを起動
- 「CSV ファイルを読み込み」ボタンをクリック
- データが美しく表示されることを確認
page_data_load.py(全体)
import os
import flet as ft
import pandas as pd
def load_initial_csv_data(page: ft.Page):
"""CSVファイルからデータを読み込む関数"""
data_folder_path = "data"
explanatory_variables_file = "explanatory_variables.csv"
explanatory_variables_path = os.path.join(
data_folder_path, explanatory_variables_file
)
target_variable_file = "target_variable.csv"
target_variable_path = os.path.join(data_folder_path, target_variable_file)
try:
# 説明変数データの読み込み
explanatory_df = pd.read_csv(explanatory_variables_path)
print(f"説明変数データ読み込み完了。シェイプ: {explanatory_df.shape}")
# 日付カラムを統一フォーマットに変換
explanatory_df["date"] = pd.to_datetime(
explanatory_df["時点"], format="%Y年%m月"
).dt.strftime("%Y%m")
# 目的変数データの読み込み
target_df = pd.read_csv(target_variable_path, dtype={"date": str})
print(f"目的変数データ読み込み完了。シェイプ: {target_df.shape}")
# 両方のデータフレームを結合
merged_df = pd.merge(explanatory_df, target_df, on="date", how="inner")
# アプリケーションデータに保存
page.app_data.merged_df = merged_df # type: ignore
print(f"データ結合完了。シェイプ: {merged_df.shape}")
return merged_df
except Exception as e:
print(f"CSVデータのロード中にエラーが発生しました: {e}")
return None
def create_data_table(df: pd.DataFrame) -> ft.Container:
"""データフレームを表示用テーブルに変換する関数"""
# ヘッダー行の作成
header_row = ft.Row(
controls=[
ft.Container(
content=ft.Text(col, weight=ft.FontWeight.BOLD, size=14),
width=200,
padding=ft.padding.only(left=15, right=15, top=8, bottom=8),
border=ft.border.only(
right=ft.border.BorderSide(1, ft.Colors.GREY_300)
),
)
for col in df.columns
],
alignment=ft.MainAxisAlignment.START,
)
# データ行の作成
data_listview = ft.ListView(expand=True, spacing=0, padding=0)
for row in df.itertuples(index=False):
data_row = ft.Row(
controls=[
ft.Container(
content=ft.Text(str(value), size=14),
width=200,
padding=ft.padding.only(left=15, right=15, top=8, bottom=8),
border=ft.border.only(
right=ft.border.BorderSide(1, ft.Colors.GREY_300)
),
)
for value in row
],
alignment=ft.MainAxisAlignment.START,
)
# 交互の行の背景色を設定(Containerでラップ)
if len(data_listview.controls) % 2 == 1:
data_row = ft.Container(
content=data_row,
bgcolor=ft.Colors.GREY_50,
)
data_listview.controls.append(data_row)
# テーブル全体を包むスクロール可能なコンテナ
table_container = ft.Container(
content=ft.Column(
[
# ヘッダー行(固定)
ft.Container(
content=header_row,
border=ft.border.only(
left=ft.border.BorderSide(1, ft.Colors.GREY_300),
right=ft.border.BorderSide(1, ft.Colors.GREY_300),
top=ft.border.BorderSide(1, ft.Colors.GREY_300),
),
bgcolor=ft.Colors.GREY_100,
),
# データ行(スクロール可能)
ft.Container(
content=data_listview,
border=ft.border.only(
left=ft.border.BorderSide(1, ft.Colors.GREY_300),
right=ft.border.BorderSide(1, ft.Colors.GREY_300),
bottom=ft.border.BorderSide(1, ft.Colors.GREY_300),
),
expand=True,
),
],
spacing=0,
expand=True,
),
expand=True,
)
return table_container
def data_load_page(page: ft.Page):
"""データ読み込みページ"""
page.title = "データ読み込み・参照"
# データ表示用コンテナ
content_container = ft.Container(
content=ft.Text("データを読み込んでください"),
bgcolor=ft.Colors.WHITE,
expand=True,
)
def load_data_button_click(e):
"""データ読み込みボタンのクリックイベント"""
try:
# CSVファイルからデータを読み込み
merged_df = load_initial_csv_data(page)
if merged_df is not None and not merged_df.empty:
# データテーブルを作成して表示
table_container = create_data_table(merged_df)
content_container.content = table_container
# 成功メッセージを表示
snack = ft.SnackBar(content=ft.Text("データの読み込みが完了しました!"))
page.add(snack)
snack.open = True
else:
# エラーメッセージを表示
snack = ft.SnackBar(content=ft.Text("データの読み込みに失敗しました。"))
page.add(snack)
snack.open = True
except Exception as e:
print(f"データ読み込み中にエラーが発生: {e}")
snack = ft.SnackBar(content=ft.Text(f"エラーが発生しました: {str(e)}"))
page.add(snack)
snack.open = True
page.update()
# データ読み込みボタン
load_button = ft.ElevatedButton(
"CSVファイルを読み込み",
on_click=load_data_button_click,
style=ft.ButtonStyle(
color=ft.Colors.WHITE,
bgcolor=ft.Colors.BLUE,
),
)
return ft.Container(
content=ft.Column(
[
ft.Text("データ読み込み・参照", size=20, weight=ft.FontWeight.BOLD),
ft.Divider(),
load_button,
ft.Divider(),
content_container,
],
expand=True,
),
expand=True,
)
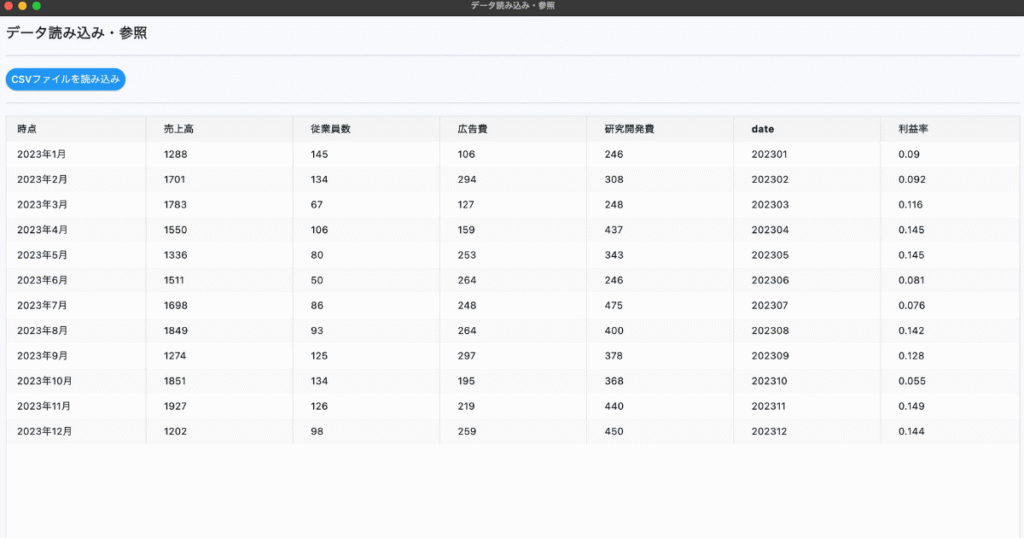
main.pyを実行し、こんな画面が出てきたらOKです。
よくあるエラーと対処法
1. FileNotFoundError
原因:CSV ファイルが見つからない
対処法:dataフォルダに CSV ファイルが存在することを確認
2. UnicodeDecodeError
原因:文字エンコーディングの問題
対処法:encoding="utf-8-sig"を指定
3. ValueError: time data does not match format
原因:日付フォーマットが期待と異なる
対処法:日付フォーマットを確認し、`format`パラメータを調整
4. Catching too general exception Exception
原因:except Exception:で全ての例外をキャッチしている
対処法:この警告は無視してOK!初心者向けのコードでは問題ありません
理由:学習段階では、まず基本的な例外処理を理解することが重要です
次回予告
今回はCSVファイルを読み込んで画面に表示するところまでを解説しました。
次回は、読み込んだデータに対してデータ変換機能(対数変換、差分化、標準化など)を実装していきます。
データ変換は金額とパーセンテージなど単位の違いが大きいデータ同士を分析するのために必須の処理です。
pythonを使うことで統計分析に必要な前処理を簡単に行えるようになります。
お楽しみに!

コメント